During my recent experience at Structure:Europe I have engaged in a discussion regarding whether the “workload” should “care” about the cloud or not. It is a great topic to debate on and I decided to write a few more thoughts here below. But let me recall the conversation first.
The trigger was a sentence by @ditlev, CEO of OnApp, that we also heard during his session with @tonylucas during the second day of Structure, and that I commented on Twitter with:
.@richtwarner @Ditlev workloads care about the #cloud because they need to control and orchestrate the infrastructure in order to scale
— Marco Meinardi (@meinardi) September 18, 2013
Among others, @khushil, engineer at Mail Online, did not agree with me as we read his tweet replying: “wrong way around, the cloud needs to understand the workload to scale to support. other way misses the point“.
Ditlev obviously picked this up and explained further that “workloads should be agnostic, your infrastructure (incl cloud)/platform should adapt” and that he would “like to see abstraction layers between workloads and infrastructure“.
What’s the source of the workload?
One may be confused and agree in principle with everyone, as every tweet seems to be reasonable, but I think first we should make some assumptions upfront, starting from the definition of workload:
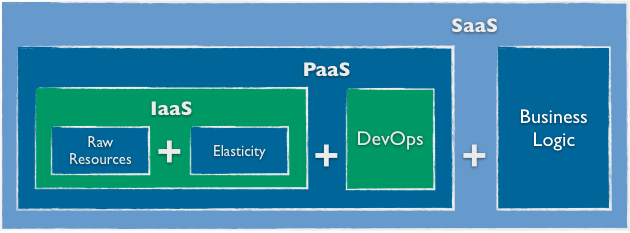
In computer science, we indeed have several abstraction layers and that happens also with cloud computing (more insights in one of my previous post here). In such scenario, however, there are also many “entities” performing some work at those different layers. So which one is the entity whose workload we were talking about? Given what our companies do, I bet we were referring to cloud infrastructures handling and processing work that is generated by applications running on top of them.
Clarified the context, I shall explain why applications should instead care about the cloud without expecting any magic to happen down there.
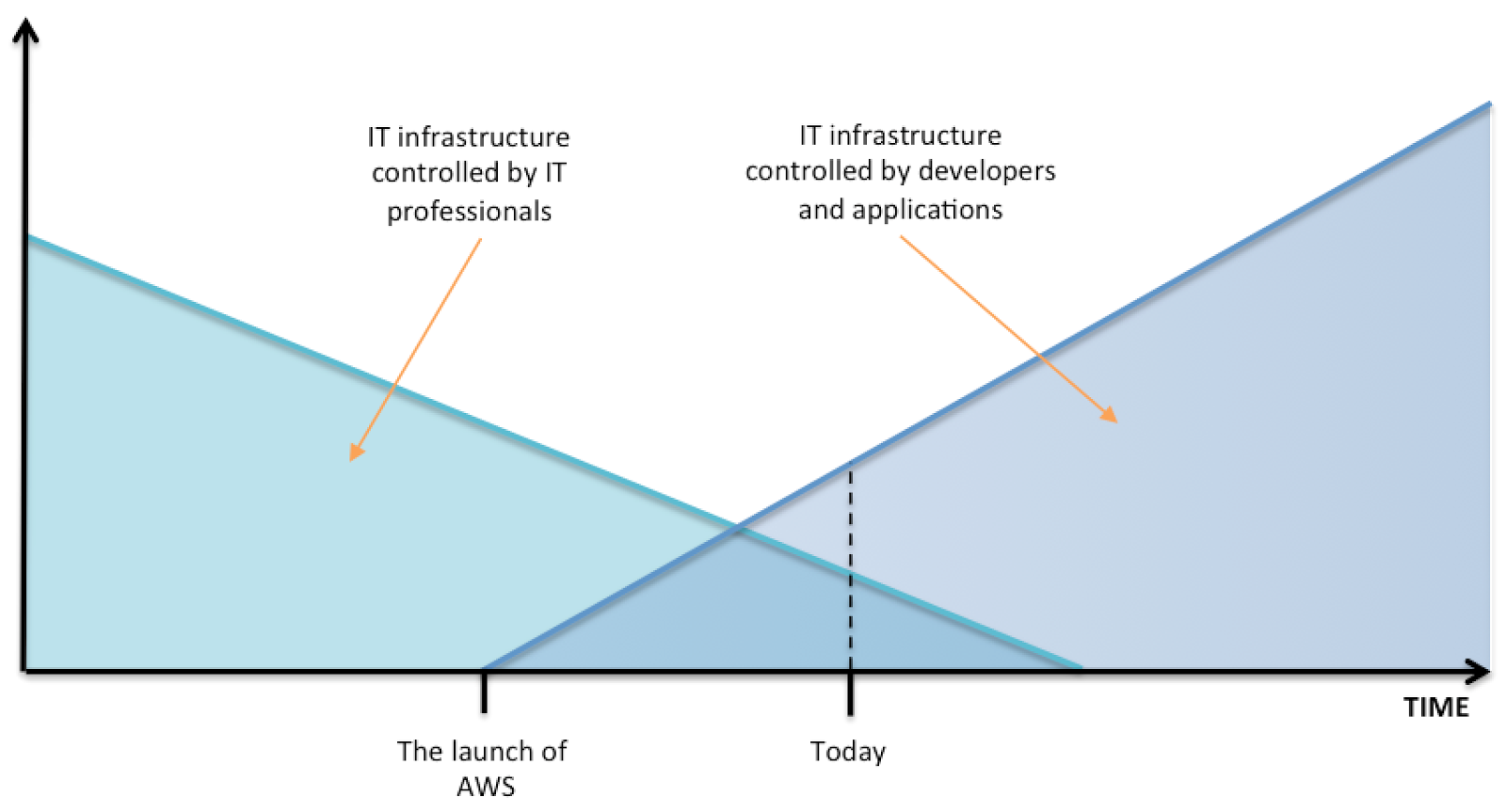
The new era of IT infrastructures
We are witnessing a tremendous change in the core functioning of IT infrastructures. Up to the advent of cloud computing, the general approach taken by IT professionals was to manually provision a specific footprint made of servers, CPUs, memory, storage and network devices. That footprint was probably over-sized in order to accommodate predictable workload growth over time. Applications were designed to abstract from infrastructures, they were simply demanding more CPU cycles or IOPS whenever they wanted to, regardless of the actual availability. The result of this approach has been a tremendous increase in the total cost of ownership of IT departments. Hardware was required to be reliable, fast and able to accommodate peaks in workload without any performance loss. This all came at a price.
Two main drivers came to disrupt and trigger a drastic change. The first one is mobile computing, i.e. the demand of Internet services that suddenly became ubiquitous, leading the generation of unpredictable workload demand from anywhere in the world, at any time of the day. The second driver is the growing availability of a large quantity of data, user and machine generated Big Data, that require to be stored and analyzed.
To accommodate the above scenarios, IT infrastructures had to become completely software-driven, highly elastic and extremely scalable. With cloud infrastructures, today it is in fact possible to provision an infrastructure footprint using a few mouse clicks or a couple of functions within a few lines of code. The size of the infrastructure can be adapted to the required workload in a specific moment, no more need to over-provision, as resources can grow and shrink using few simple automatic operations.
And with the availability of software-consumable infrastructures, also applications are changing their approach, becoming much more infrastructure-aware. In fact, in case of resource shortage, applications can request for more by using API calls, growing the infrastructure footprint as required. At the same way, they’re now able to handle faults, making expensive highly available infrastructures completely worthless! (I blogged about this before here).
Think application!
All of this to explain that no, the cloud (infrastructure) does not have to understand the workload and does not have to automatically adapt to it. Even if that could be theoretically possible, the infrastructure lacks of the right metrics to recognise a real need for more resources. Instead, it is the application itself that actively adapts its own infrastructure, because only the application understands how the user experience is going, which the only metric that should be taken into consideration when measuring application performance.
Are you currently auto-scaling your infrastructure based on CPU utilisation? When it happens, are you sure that corresponds to a real improvement of the user experience? Or simply to a higher bill of your cloud provider?
And what if your VM goes down? Will you blame your cloud provider and then blog about its ridiculous SLA penalty fees, that never corresponds to your real loss of business? Isn’t it more effective to make sure that you understand the VM is down and that you (your application, I mean) take the necessary step to failover elsewhere?
With a clever application, infrastructure can be seen just as a toolbox. And you need to know how to use those tools in order to build highly available, auto-scaling applications. Don’t expect your screwdriver to build on your behalf the room for your newborn baby.
Or more simply, as @AmberCoster of AppDynamics said to me in another Twitter conversation: “Think application, not just infrastructure!”.