
This blog post is a two-parts series about debugging Node.js applications. The first part focuses on post-mortem debugging tools and practices, the second part illustrates how to debug latency bubbles in production using DTrace.
Debugging Node.js latency bubbles
Soft real-time systems
One thing that came out with Node.js is that it is extremely good for the new breed of applications: Internet facing, soft real-time systems.
A real-time system is one where the timeliness of the system is also its correctness, at some level. There is a clear distinction between hard real-time systems, where being late means failing, and soft real-time systems, where being late means systems just kind of “suck”.
With the rise of mobile, social and HTML5, we’ve seen more and more of this new breed of applications – DIRTy systems (data intensive real-time systems) – that are Internet facing, real-time systems that have a human in the loop. And when humans are in the loop the good news is that deadlines are soft (the system sucks but it doesn’t die – people will just complain), but the bad news is that the demand is typically non-linear.
Let’s imagine you’ve carefully built your real-time mobile application and suddenly a DJ from Cleveland tells all his listeners that they gotta go download your app and… boom! You get 100,000 people show up the same night, 400,000 more people at the end of the week and 1 million people at the end of the month. This happens, it has happened repeatedly, and it will happen again. We are seeing this trend accelerating, and the more computers will be in our pockets, the more we will have to cope with this.
And this is why it’s extremely difficult to deal with the challenge of scalability at the same time with the challenge of delivering data in real-time.
Debugging latency with DTrace
How do you debug these systems when they go wrong? How do you debug the latency bubbles that consist of failures in these kinds of systems?
Bryan Cantrill (@bcantrill) worked extensively in building real-time systems during his career and debugging them has always been a challenge for him. So he developed DTrace to dynamically instrument those systems, being able to walk them while they’re running, grabbing timestamps at different parts of the stack and correlating them to figure out where the latency is coming from.
The question was: how could we take DTrace into Node.js?
As was true for interpreting core dumps, in interpreted environments it’s extremely difficult to figure out from the bottom what is going on at the top of the stack. Bryan and team had a bunch of ideas and one of them was taken from other interpreted environments that instrument the actual VM wherever it’s doing a function call. It’s great and powerful (Erlang did a terrific job on that) but it is too fine grained.
Eventually, they decided to add USDT (Userland Statically Defined Tracing) probes at certain points of interests like HTTP requests, HTTP responses, GC and so on.
But how can we effectively use DTrace to debug our latency in Node.js? Let’s start by listing all the probes available for all my node processes by typing the following command in a SmartOS shell:
And we’ll get an output like this:
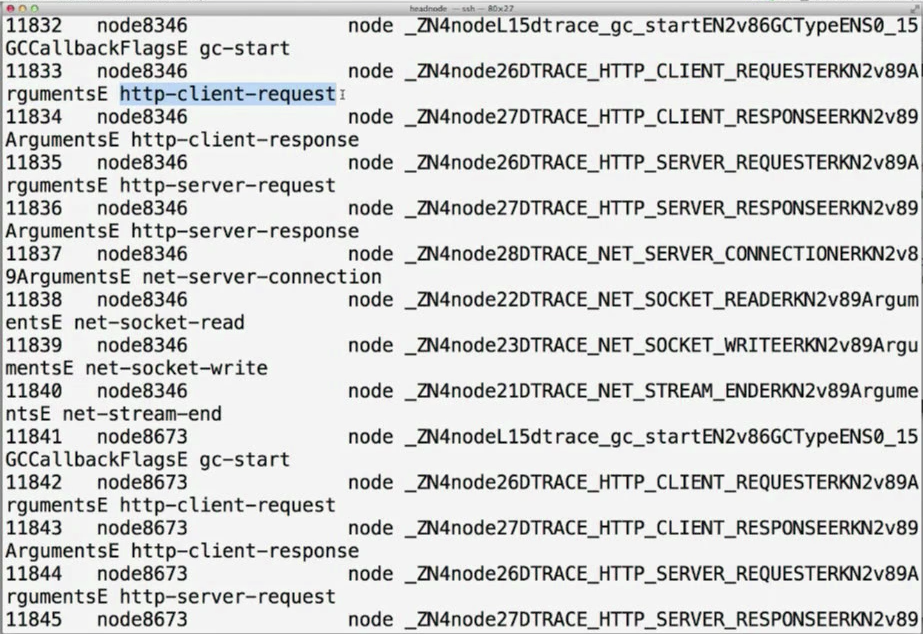
Apart from the C++ name mangling, you can actually see the points of interests (USDT probes) named http-client-request, http-client-response, etc.
Let’s go enable all of them so that we can see in real time what our node processes are doing.
On the left you can see the process IDs and on the right what they’re doing:
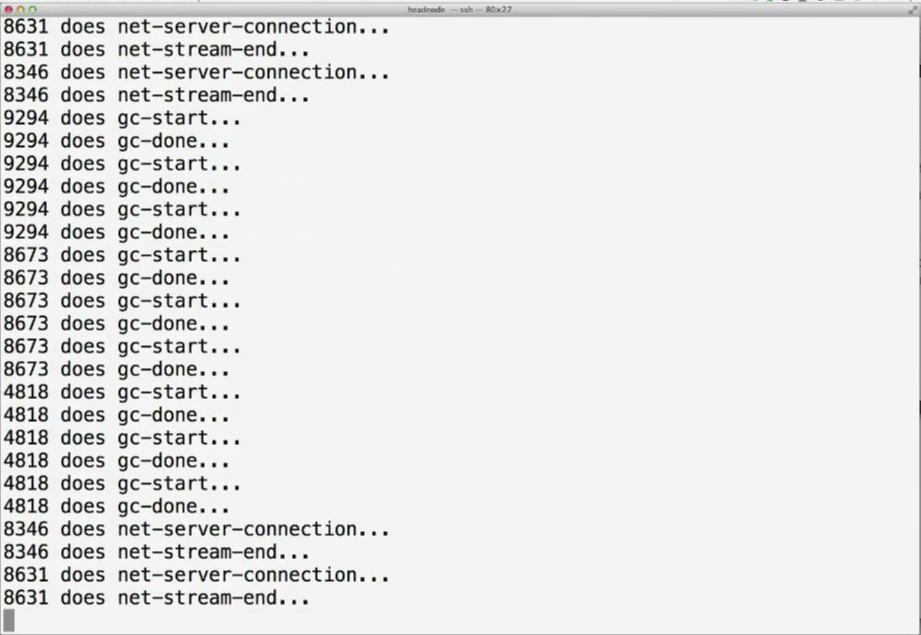
Let’s try to isolate the incoming HTTP activity by instrumenting only the http-client-request:
And we get some more information out of it:

If we want to see the code actually executed upon HTTP requests, we can generate a stack trace whenever they occur by using the ustack() function:
That prints out the stack backtrace:
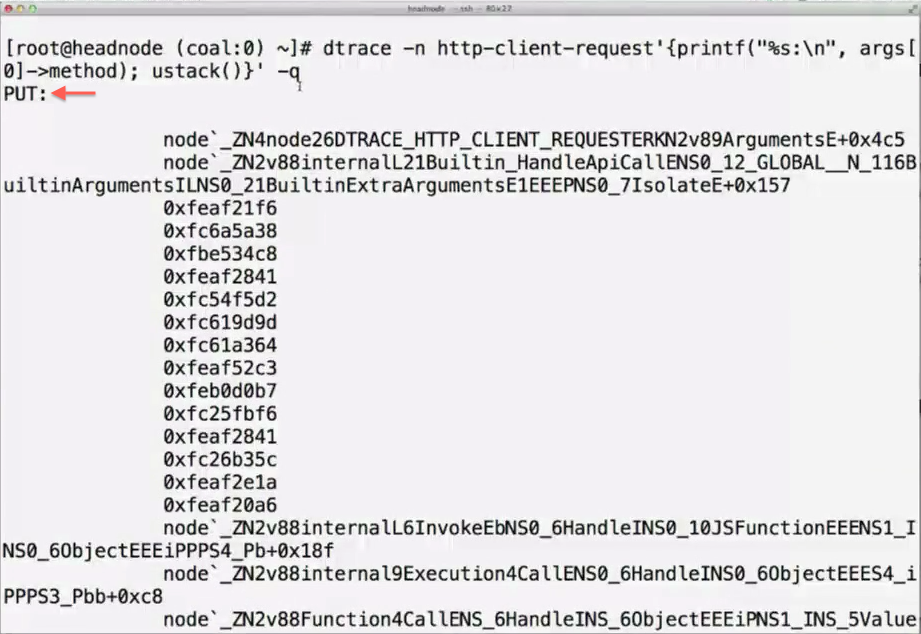
We printed the actual called method “PUT” (args[0]->method) and right after the stack trace of what was executed upon the request.
But we’re now back to the other problem: what the hell is this? Bryan and team were in front of another challenge: how to turn all of this into V8 frames from the context of the kernel?
And Dave Pacheco (@dapsays), who doesn’t know the definition of impossible (see part 1 of this blog post), has solved this for JavaScript environment. This is how: when V8 starts, it expresses in an intermediate representation how to take one of these frames and turn it into an actual string, and all of that is downloaded into the kernel upon start of the virtual machine. Then, whenever there is a stack trace generated, this time by the jstack() function, the map table is evaluated and frames are turned into proper readable ones.
Now we can see the actual JavaScript that was executed upon a GET:
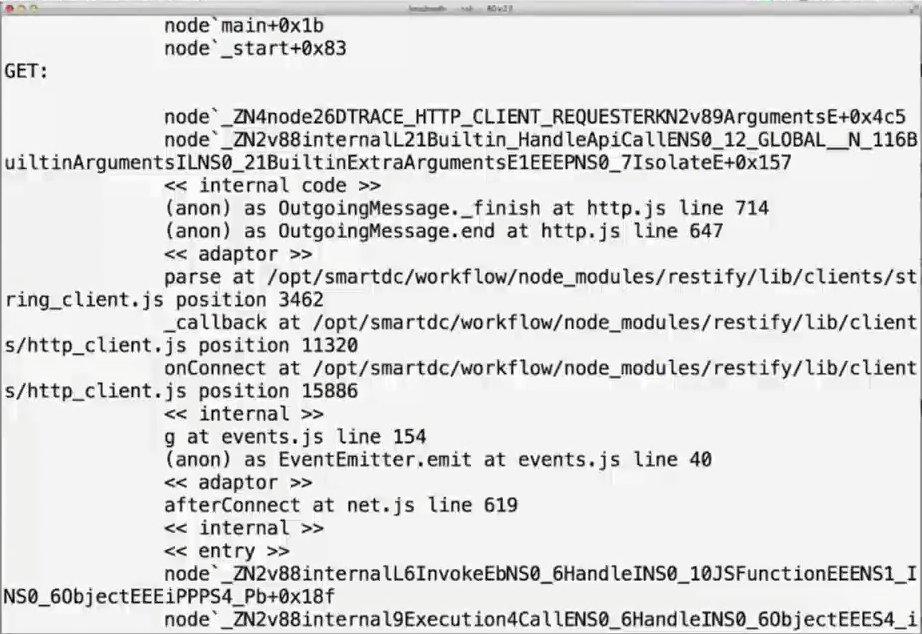
As you may have realized, this is shining a very bright light to what was previously a total black hole. If you have a Node.js program misbehaving without this kind of technology you’re hosed.
During Node Summit back in January 2012, we heard practitioners talking about big problems of Node.js, and it was all about production debuggability. This is what Joyent has invested a lot into with SmartOS, even if the truth is that we did it to debug our own problems, and that’s true also for DTrace!
The remaining challenge was that USDT methodology was difficult to use with JavaScript. Fortunately, Chris Andrews developed the Node.js DTrace provider that allows you to define your own probes (the “points of interest”) entirely using JavaScript.
All of the above is available in Node.js since 0.6.7 and it’s there by default, you don’t have to do anything to enable it.
Visualizing latency
In terms of visualizing latency, another colleague from Joyent – Brendan Gregg (@brendangregg) – has done a terrific job. One of the most common problems is Node.js programs using too much CPU. Brendan hunted it by profiling the CPU at regular intervals, taking the stack traces, aggregating them by smashing the results together, re-sorting and displaying them as a “flame graph”:
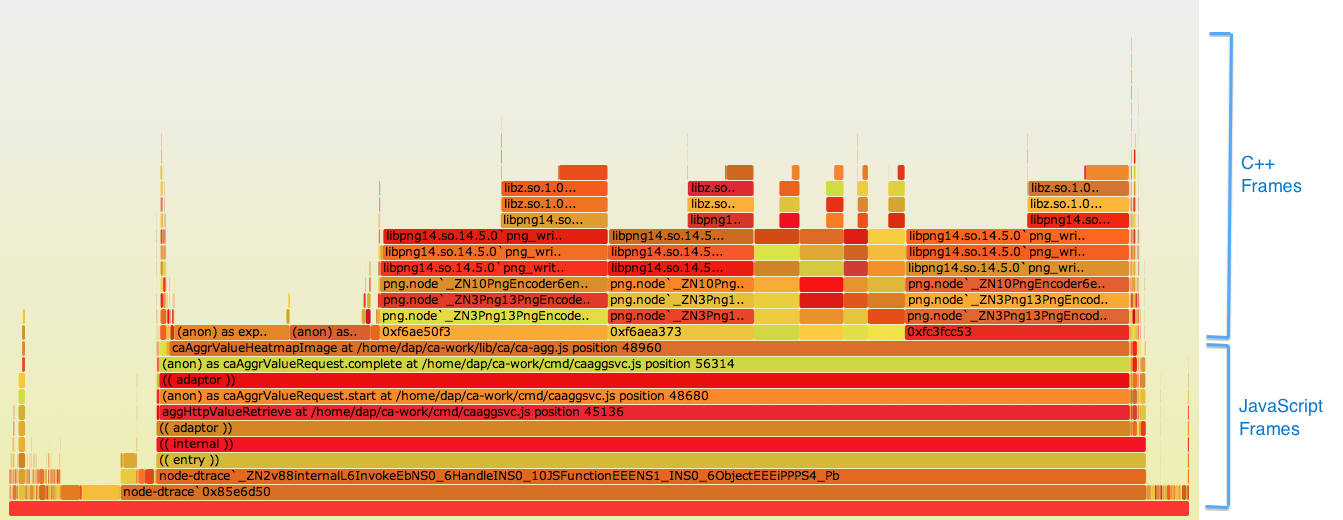
The stack shows both JavaScript and C++ frames in a way you can easily identify where your program is spending most of the CPU time. And it’s good to know is that all the tools to generate flame graphs are on GitHub and they’re open source, you can already use them in production to find important bugs or latency bubbles throughout your Node.js code.
Conclusion
SmartOS is Joyent’s foundation for the NodeStack, but Node.js runs everywhere. We, at Joyent are not binding Node.js to work only on a particular platform. We’re committed to invest further in SmartOS in a way to make it the natural choice for your production Node.js environment. And we’re going to do this by giving you great technology that allows you to understand your Node.js app in a way you can’t on any other platform.
SmartOS is an open-source project and it can be consumed as-a-service on top of the Joyent Public Cloud where all the above mentioned tools are enabled by default.
But now I would like to hear from you: how you debug your Node.js applications today? Do you consider debugging in production being one of the biggest Node.js challenges?
End of part 2. You can watch all NodeStack videos, including the one by Bryan Cantrill that was summarized here, by registering yourself for free on the conference website.
